
Redis的数据概览
Redis为啥这么快?
除了它是内存数据库,使得所有的操作都在内存上进行之外,还有一个重要因素,就是它实现的数据结构,使得我们对数据进行增删改查操作时,Redis能高效的处理。
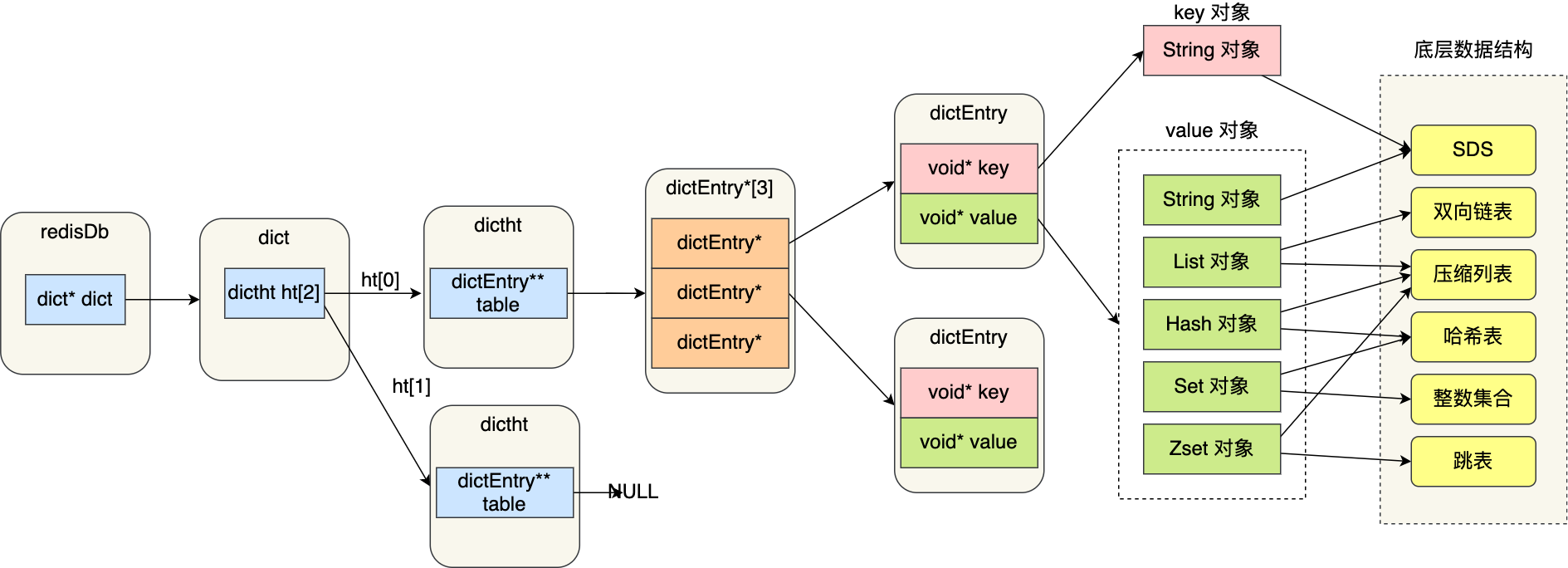
键值对数据库是怎么实现的?
Redis 的键值对中的 key 就是字符串对象,而 value 可以是字符串对象,也可以是集合数据类型的对象,比如 List 对象、Hash 对象、Set 对象和 Zset 对象。
大致图
SDS
字符串在 Redis 中是很常用的,键值对中的键是字符串类型,值有时也是字符串类型。
Redis 是用 C 语言实现的,但是它没有直接使用 C 语言的 char* 字符数组来实现字符串,而是自己封装了一个名为简单动态字符串(simple dynamic string,SDS) 的数据结构来表示字符串,也就是 Redis 的 String 数据类型的底层数据结构是 SDS。
C语言字符串的缺陷
- 首先的话,因为C语言是通过判断是否有’\0’来决定字符串是否结束,所以C语言获取字符串长度的时间复杂度是O(N)(这是第一点)
- 因为C语言的字符串是不会记录自身的缓冲区大小,所以字符串操作函数不高效且不安全,会有缓存区溢出的风险,可能会造成程序综止。
- 因为C语言是通过判断是否有’\0’来决定字符串是否结束,字符串里面不能含有 “\0” 字符,所以不能保存图片,音频,视频文化这样的二进制数据。
SDS结构设计
Redis 5.0 的 SDS 的数据结构:

结构中的每个成员变量分别介绍下:
- len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
- alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。
- flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。
- buf[],字节数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
扩容的机制
|
|
- 如果所需的 sds 长度小于 1 MB,那么最后的扩容是按照翻倍扩容来执行的,即 2 倍的newlen
- 如果所需的 sds 长度超过 1 MB,那么最后的扩容长度应该是 newlen + 1MB。
并且从这个扩容机制来看,SDS不仅会获得修改所必要的空间,还会得到额外的空间,这样的话可以有效的减少内存分配次数。
节省内存空间
Redis 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
这 5 种类型的主要区别就在于,它们数据结构中的len 和 alloc 成员变量的数据类型不同。
之所以 SDS 设计不同类型的结构体,是为了能**灵活保存不同大小的字符串,**从而有效节省内存空间。
还使用了专门的编译优化来节省内存空间,告诉编译器取消结构体在编译过程中的优化对齐,按照实际占用字节数进行对齐。
链表
链表的优势和劣势
Redis 的链表实现优点如下:
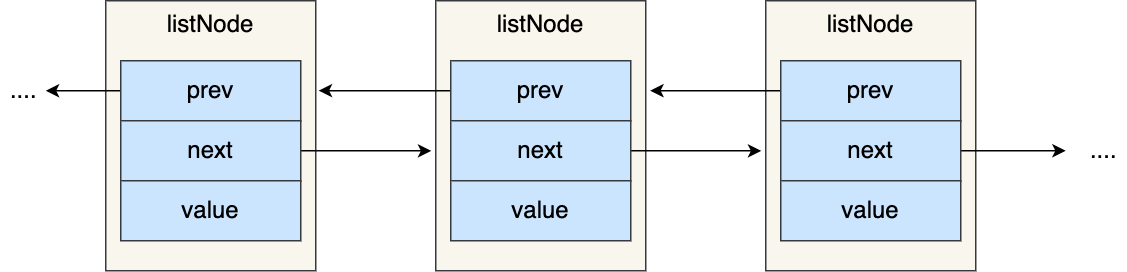
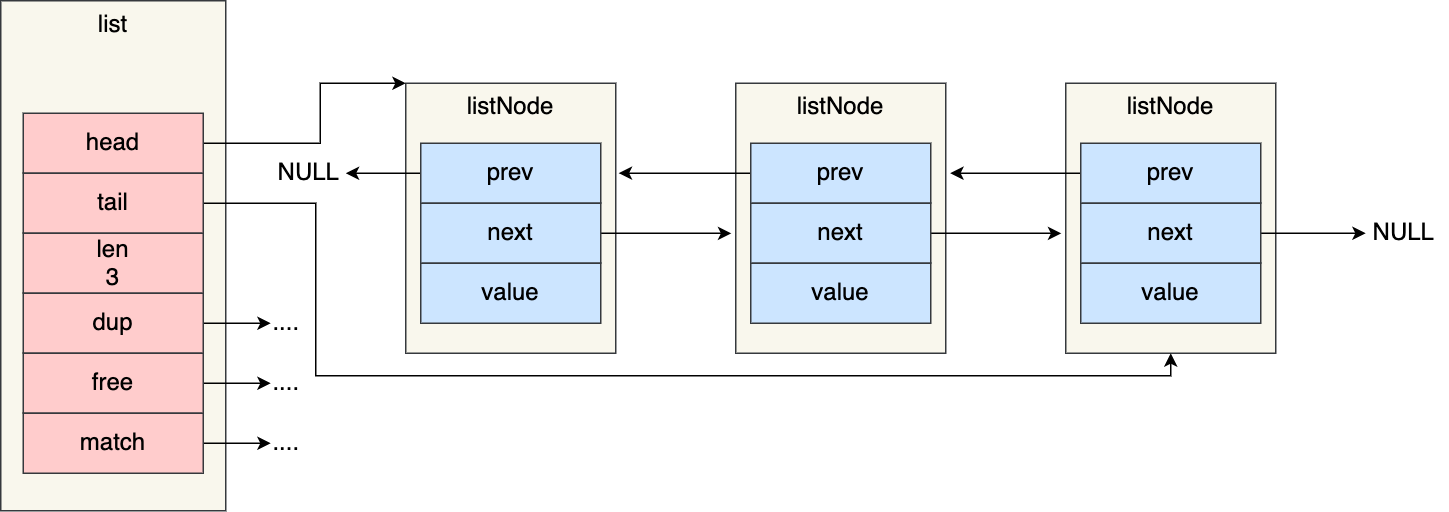
- listNode 链表节点的结构里带有 prev 和 next 指针,获取某个节点的前置节点或后置节点的时间复杂度只需O(1),而且这两个指针都可以指向 NULL,所以链表是无环链表;
- list 结构因为提供了表头指针 head 和表尾节点 tail,所以获取链表的表头节点和表尾节点的时间复杂度只需O(1);
- list 结构因为提供了链表节点数量 len,所以获取链表中的节点数量的时间复杂度只需O(1);
- listNode 链表节点使用 void* 指针保存节点值,并且可以通过 list 结构的 dup、free、match 函数指针为节点设置该节点类型特定的函数,因此链表节点可以保存各种不同类型的值;
链表的缺陷也是有的:
-
链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存。能很好利用 CPU 缓存的数据结构就是数组,因为数组的内存是连续的,这样就可以充分利用 CPU 缓存来加速访问。
-
还有一点,保存一个链表节点的值都需要一个链表节点结构头的分配,内存利用率较低。