
MySql内部结构
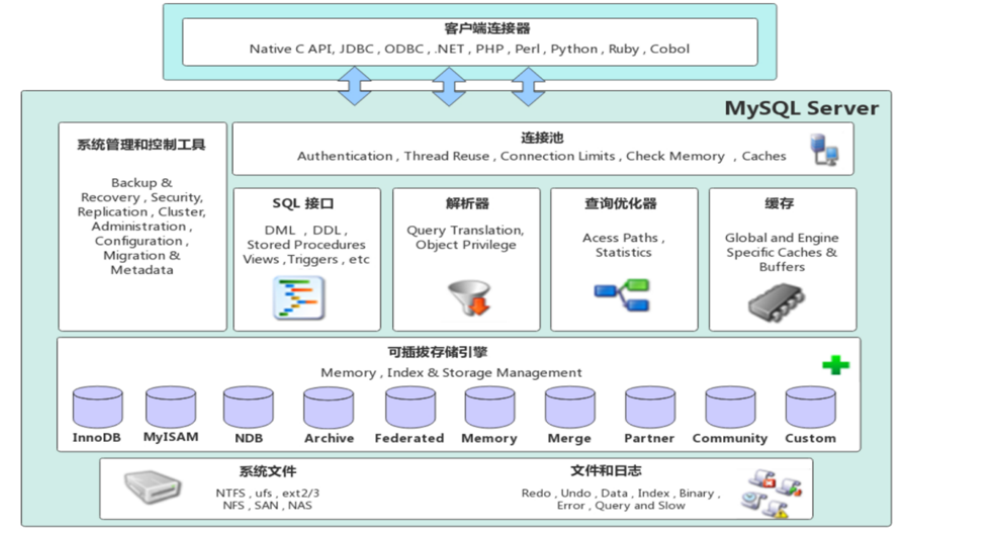
执行一条select语句,期间发生了啥?
先说结论
- 首先客户端会与服务端的连接器进行连接,连接器会检查客户端传来的账号,密码,核对一下是否正确,如果正确,就会开始读取所属的用户和用户权限,并把这个信息保存在连接器中,如果不正确,会返回错误。
- 然后开始查询缓存(针对已经查过的数据,会以key-value的形式存储在缓存中),如果key中有对应的值,则直接返回其value值。(MySQL 8.0已经删除这个模块)
- 其次会解析SQL,解析器会先进行词法分析,然后进行语法分析,构造语法树,如果语法错误,会返回错误。
- 最后执行SQL,首先在预处理器中会判断是否缺少字段,然后在优化器中选择合适的SQL查询方案,尽可能地提高性能,最后在执行器中按照执行计划执行SQL查询语句,从存储引擎读取记录,返回给客户端。
逐步分析
连接器
- 与客户端进行 TCP 三次握手建立连接;
- 校验客户端的用户名和密码,如果用户名或密码不对,则会报错;
- 如果用户名和密码都对了,会读取该用户的权限,然后后面的权限逻辑判断都基于此时读取到的权限;
查询缓存
- 如果 SQL 是查询语句(select 语句),MySQL 就会先去查询缓存( Query Cache )里查找缓存数据,看看之前有没有执行过这一条命令,这个查询缓存是以 key-value 形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL 语句查询的结果。
- 如果查询的语句命中查询缓存,那么就会直接返回 value 给客户端。如果查询的语句没有命中查询缓存中,那么就要往下继续执行,等执行完后,查询的结果就会被存入查询缓存中。
- 其实这个很无用(对于更新比较频繁的表,查询缓存的命中率很低的,因为只要一个表有更新操作,那么这个表的查询缓存就会被清空。如果刚缓存了一个查询结果很大的数据,还没被使用的时候,刚好这个表有更新操作,查询缓冲就被清空了,相当于缓存了个寂寞。),所以MySQL 8.0 版本直接将查询缓存删掉了。
解析SQL
- 第一件事,词法分析。MySQL 会根据你输入的字符串识别出关键字出来,例如,SQL语句 select username from userinfo,在分析之后,会得到4个Token,其中有2个Keyword,分别为select和from;
- 第二件事语法分析。根据词法分析的结果,语法解析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法,如果没问题就会构建出 SQL 语法树,这样方便后面模块获取 SQL 类型、表名、字段名、 where 条件等等。
执行SQL
- 预处理器
- 检查 SQL 查询语句中的表或者字段是否存在;
- 将 select Fields 中的内容扩展为该有的列;
- 优化器
- 主要负责将SQL查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。
- 执行器
- 主键索引查询
- 全表扫描
- 索引下推
最终的效果图
MySql的数据存放在哪个文件?
- 对于MySql5.7来说

- db.opt,用来存储当前数据库的默认字符集和字符校验规则。
- student.frm,student的表结构会保存在这个文件中。
- student.ibd,student的表数据会保存在这个文件中。
- 对于MySql8.0来说
- 这个ibd文件中不仅存放表结构、数据,还会存放该表对应的索引信息。
表空间文件的结构是啥?
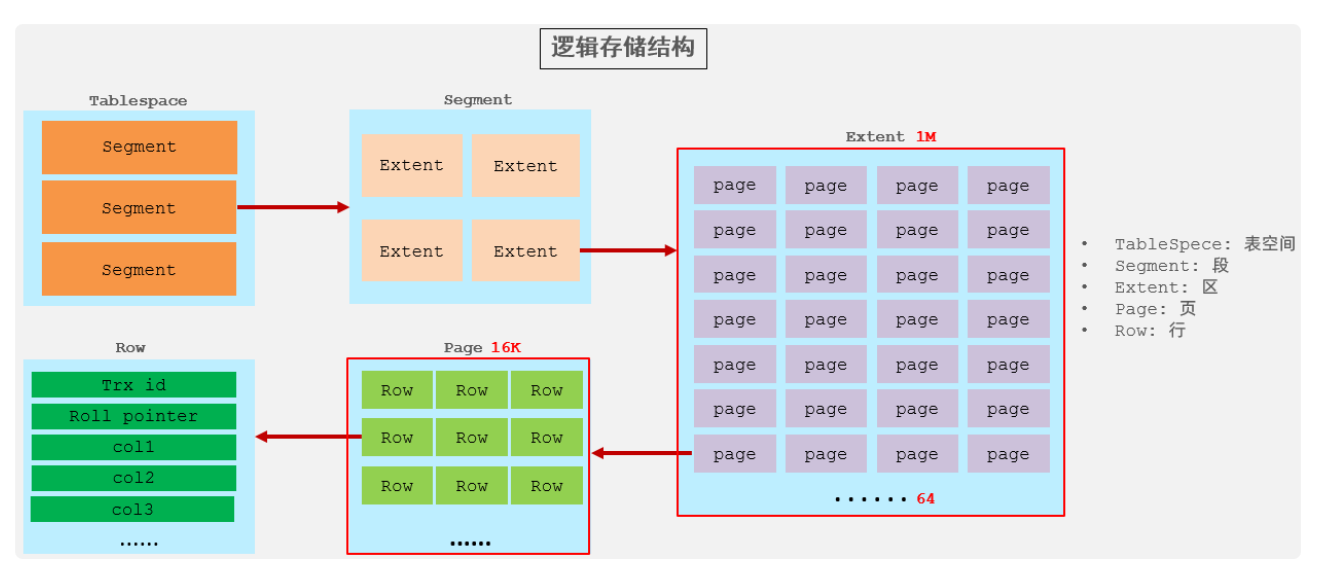
- 表空间 : InnoDB存储引擎逻辑结构的最高层,ibd文件其实就是表空间文件,在表空间中可以包含多个Segment段。
- 段 : 表空间是由各个段组成的, 常见的段有数据段、索引段、回滚段等。InnoDB中对于段的管理,都是引擎自身完成,不需要人为对其控制,一个段中包含多个区。
- 区 : 区是表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
- 页 : 页是组成区的最小单元,页也是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。
- 行 : InnoDB 存储引擎是面向行的,也就是说数据是按行进行存放的。
InnoDB 行格式有哪些?
InnoDB 提供了 4 种行格式,分别是 Redundant、Compact、Dynamic和 Compressed 行格式。
- Redundant 是很古老的行格式了, MySQL 5.0 版本之前用的行格式,现在基本没人用了。
- 由于 Redundant 不是一种紧凑的行格式,所以 MySQL 5.0 之后引入了 Compact 行记录存储方式,Compact 是一种紧凑的行格式,设计的初衷就是为了让一个数据页中可以存放更多的行记录,从 MySQL 5.1 版本之后,行格式默认设置成 Compact。
- Dynamic 和 Compressed 两个都是紧凑的行格式,它们的行格式都和 Compact 差不多,因为都是基于 Compact 改进一点东西。从 MySQL5.7 版本之后,默认使用 Dynamic 行格式。
COMPACT 行格式长什么样?
主要分为真实数据和额外的信息,图如下
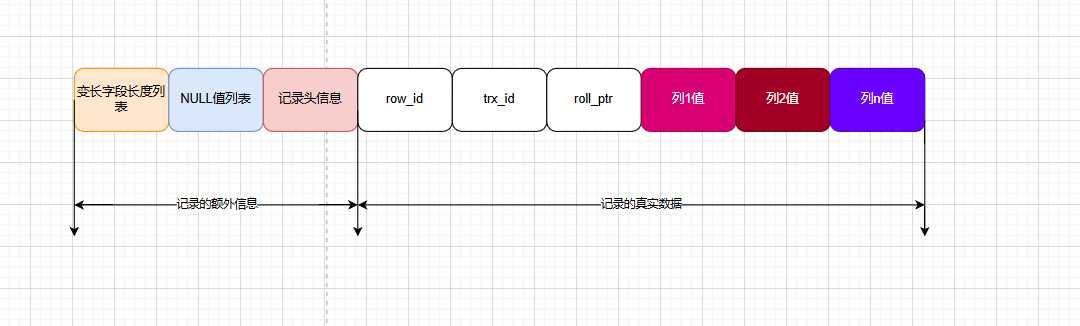
为什么「变长字段长度列表」的信息要按照逆序存放?
- 逆序存放变长字段长度列表可以使得位置靠前的记录的真实数据和数据对应的字段长度信息同时在一个CPU Cache Line中。这有助于提高CPU缓存的命中率,从而加快数据访问速度。
- 当读取记录时,首先读取的是记录头信息,然后根据变长字段长度列表中的信息,从后往前读取各个字段的长度,进而确定每个字段的起始位置和长度。
- 这种设计还有助于减少磁盘I/O操作,因为相关的长度信息和数据可以一起被加载到内存中,减少了额外的读取次数。
varchar(n)最大取值为多少?
不管是单字段还是多字段,算 varchar(n) 中 n 最大值时,都需要减去 「变长字段长度列表」和 「NULL 值列表」所占用的字节数的。
行溢出后,MySQL是咋处理的?
InnoDB存储引擎会自动将溢出的数据存放到[溢出页]中。
- Compact行溢出时,会保存该列的一部分数据,而把剩余的数据放在[溢出页]中,然后真实数据处用20字节存储指向溢出页的地址,从而可以找到剩余数据的页。
- Compressed和Dynamic这两种格式采用完全的行溢出方式,记录的真实数据处不会存储该列的一部分数据,只存储20个字节的指针来指向溢出页。而实际的数据都存储在溢出页中。